






自然言語処理
自然言語処理
テキストデータから新しい価値を発見する自然言語処理技術の研究開発を実施しています。
メディアや医療などの業務DXへ貢献する技術を開発することを目指しています。
指定用語識別技術
フリーテキストから特定の用語を識別する仕組みを確立することを目指した研究を行っています。
テキストデータから個人情報(氏名など)を識別・マスキングすることでデータの利活用に役立てたり、電子カルテなどの医療文書から病名や検査名などの情報を抽出し、医療支援に役立てることができます。
応用例
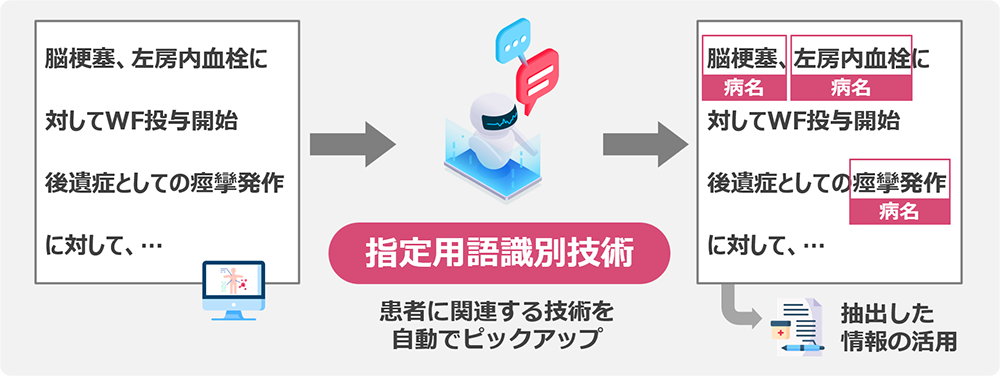
①医療文書からの患者情報の抽出
- 医療文書から患者に関わる情報(病名、検査名など)を抽出して、リスクのある患者のピックアップなどに活用できます。
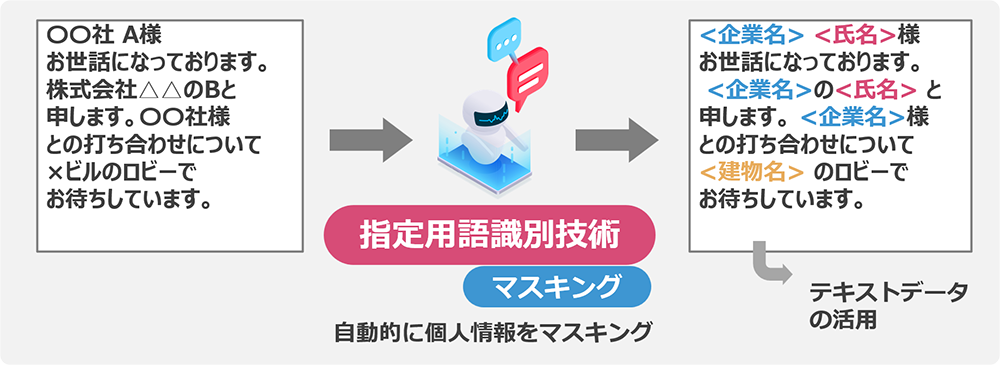
②フリーテキスト内の個人情報のマスキング
- テキスト中の氏名や住所など個人情報につながるワードを自動的にマスキングできます。
アスペクト感情分析技術
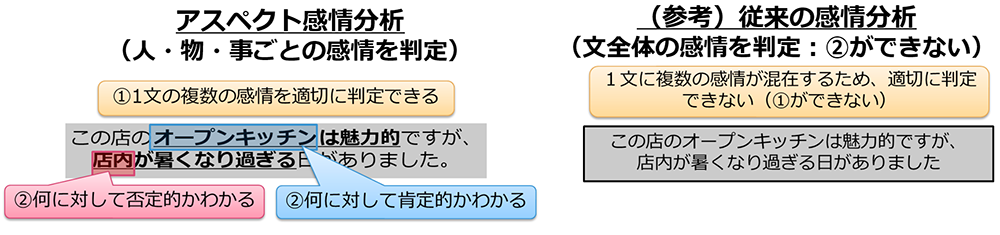
文書中の人・物・事に対する感情(肯定的 or 中立的 or 否定的)を判定でき、以下の優れた特徴を持ちます。
-
1. 1つの文に複数の感情が含まれる場合も、それらを適切に判定可能。
-
2. 何に対する感情かまでを判定可能。
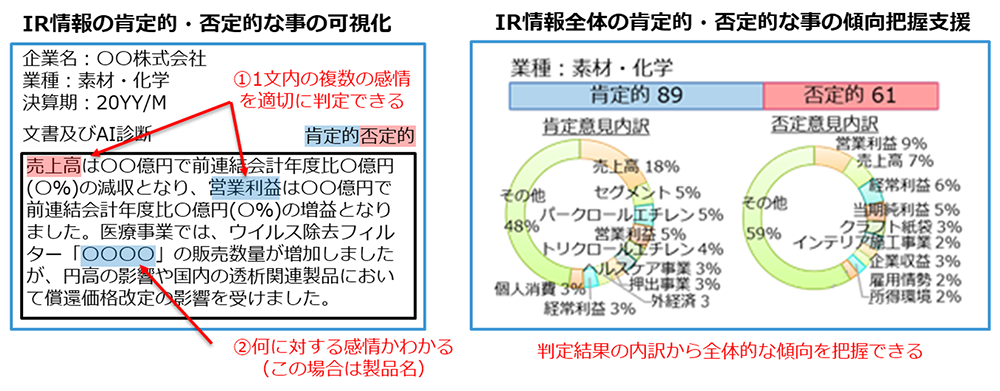
例えば、決算短信などのIR情報から、企業の成長性の観点で肯定的、否定的に書かれている事を自動判定し、金融業務に役立てることができます。
大規模言語モデル活用
ChatGPTなどのLLM(大規模言語モデル)を活用したビジネスの実現を目指し、研究開発を進めています。
下記の検証を通して、 LLMに関する技術蓄積・LLMの活用検討を進めています。
- Azure OpenAI Serviceを用いて業務データと連携した社内FAQシステムの構築および検証
- 社内商品データや顧客データを用いた営業活動の支援でのLLMの活用検討
- 話題推定技術へのLLMの適用可能性の検討および評価
社内情報システムの問合せ業務へのChatGPT活用を見据えた検証
業務課題
- 社内情報システムの社員からの問合せ業務において、質問を受けてから回答するまでに数日を要する
- 問合せ業務担当者の問合せ対応の業務負荷が高い
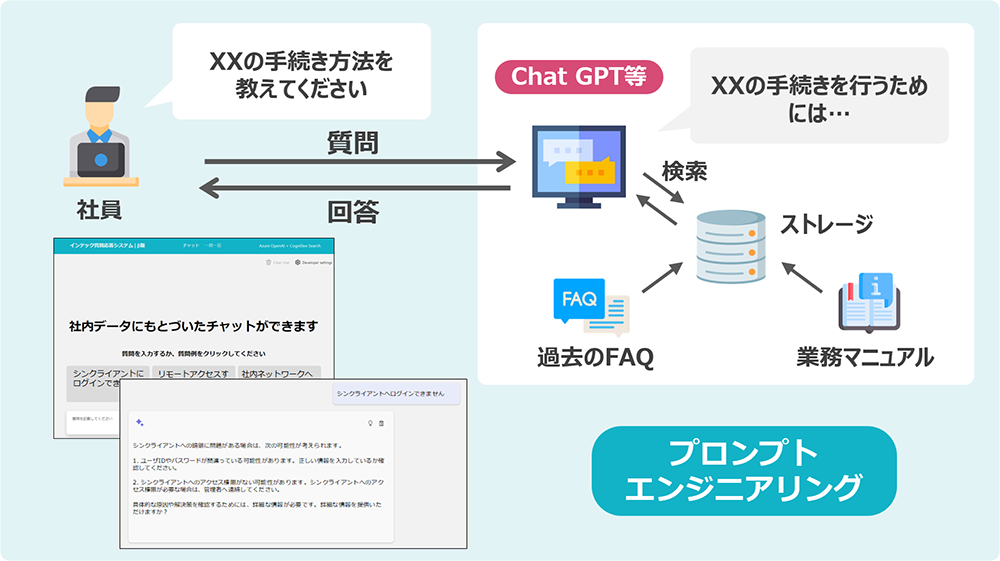
期待される効果
- 回答するまでの時間短縮を図れる
- 質問回答要員の負荷軽減につながる
分かったこと
- 事実とは異なる回答をする場合への対応(回答の根拠を表示して回答の正当性を確認する運用をする、など)
- 過去のFAQやマニュアル、表形式のデータなど、様々な形式のあるデータの登録の仕方は工夫が必要
今後の展望
- 信頼できる回答を生成する仕組み
- 質問に個人情報などふさわしくない情報が入っていないかチェックする仕組みなど
